Observability
2025年版Kubernetesリソース管理の極意:デフォルト制限とHPAの先を行く
Kubernetesにおけるワークロードのプロファイル作成、CPU/メモリのリクエスト、制限、HPAを2025年に向けてマスターする方法—ベストプラクティス、YAMLスニペット、実際の事例を交えて解説。
Younes Hairej11 min read
Kubernetesにおけるワークロードのプロファイル作成、CPU/メモリのリクエスト、制限、HPAを2025年に向けてマスターする方法—ベストプラクティス、YAMLスニペット、実際の事例を交えて解説。

Kubernetesにおけるリソース管理は常にバランスを取る事を考える作業が多々ありました2025年に向けてそのアプローチは変わりつつあります。クラスターが大規模化し、マルチテナント環境が増加する中で、単に任意のCPU制限やデフォルトのHPA設定を適用するだけではもはや十分ではなくなってきています。Aokumoでは、2つの極端な状況を目の当たりにしてきました。ひとつは、過度に厳しい制限によってスロットリングされたワークロード、もうひとつは「ノイジー・ネイバー(騒がしい隣人)」によってクラスターが不安定化するケースです。
では、どうすればこれらを回避できるのでしょうか?その秘密は、ワークロードを深く理解することにあります。それはCPU集中的なのか、メモリに依存しているのか、それともバースト処理が多いバッチジョブなのか、原因を理解するところから始まります。
そして次に必要なのは観測可能なデータに基づいてリクエスト、制限、オートスケーリングのルールを設定することです。
この記事では、CPU制限に関する議論、Horizontal Pod Autoscaler(HPA)の進化する役割、リソース設定の一般的な落とし穴、そして実践的なベストプラクティスを深掘りします。Aokumoの洞察やX(旧Twitter)での最新のコミュニティの議論を交えて解説します。
本記事は、リソース設定に関わるプラットフォームエンジニア、SRE、DevOps担当者に向けて書かれていますが、ITマネージャーにとっても、現場のチームが直面している課題の深刻さと調整の複雑さを理解する助けになるでしょう。
リクエスト、制限、HPAを設定する前に、まずは以下の質問に答えるための以下のような情報収集と分析をしましょう:
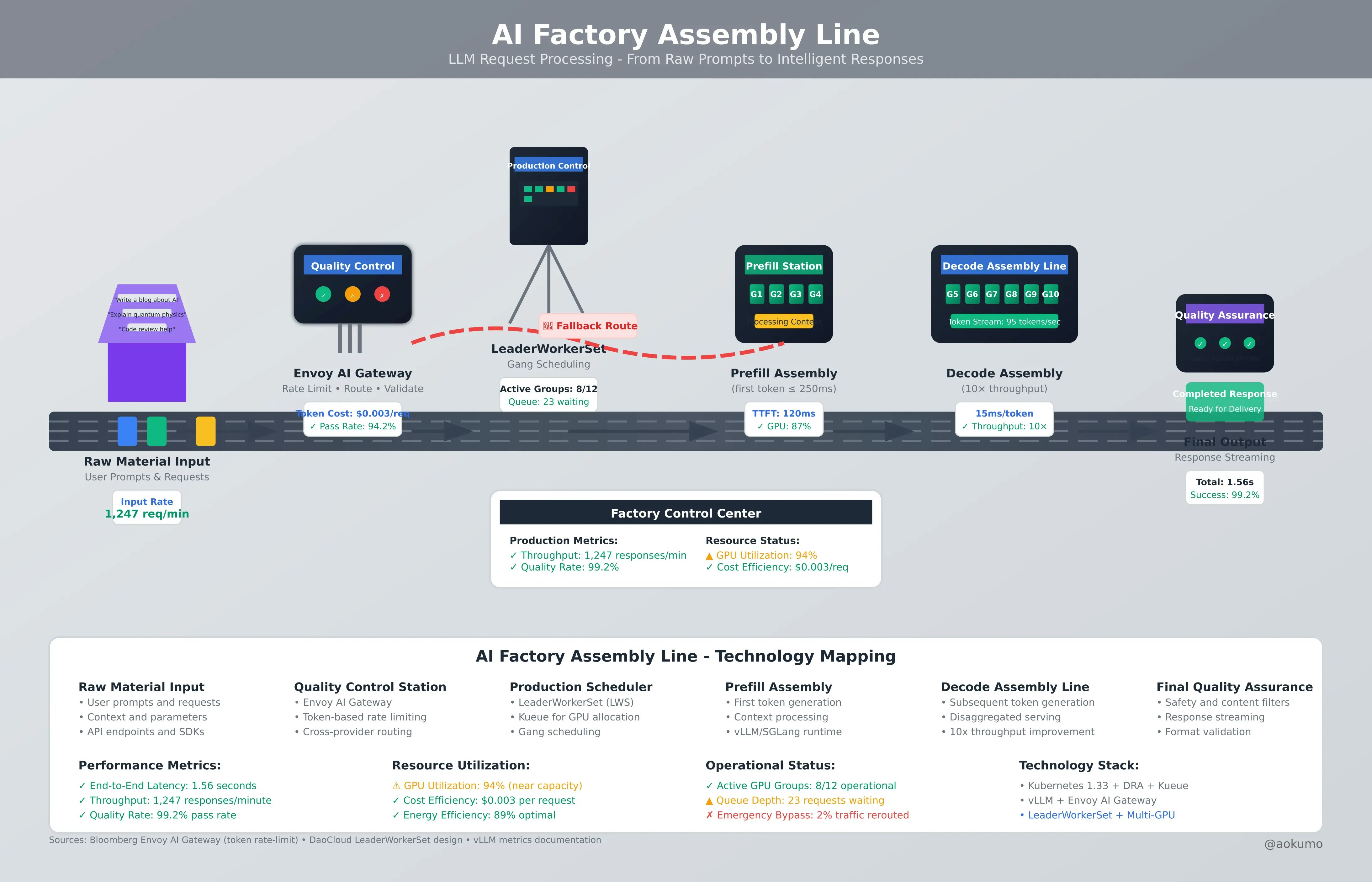
Aokumoのヒント: Prometheus(またはMetrics Server + カスタムエクスポーター)を統合し、ポッドごとのCPU/メモリの使用状況を数日間にわたって可視化します。繰り返し発生するスパイクを探しましょう。たとえば、多くのアプリケーションは起動時に300%のCPUを使い、その後50%に落ち着く場合があります。このようなパターンを観察して、リクエストが実際のベースラインを反映し、ピークだけを反映しないようにしましょう。
マルチテナントクラスタでは、クリティカルなポッドに対してQoS=Guaranteed(リクエスト=制限)を設定し、排除時に優先されるようにします。スロットリングを最小限に抑えるために、リクエストの3倍などの寛容な制限を使用し、container_cpu_cfs_throttled_seconds_totalを監視して動的に調整します。また、ResourceQuotaを組み合わせて、名前空間ごとの使用量の上限を設定します。
X(旧Twitter)では、Kubernetesのアーキテクトたちが、200~350%のCPU使用率を処理するために、CPU制限とHPAのどちらが最適かを積極的に議論しています。多くの人はピーク時にHPAを使いつつ、正確なリクエストを設定することを支持していますが、複数のテナントが共有する環境では制限が有用であると指摘しています。@k8s_engineerは「重要なのは、通常運用時にスロットリングを避けるために制限を高めに設定しリソース不足を防ぐために制限を低めに設定することだ」と述べています。
「制限なし」をデフォルトにしないでください。代わりに、ワークロードを分析し測定に基づいて、許容可能な閾値を超える真の最悪のスパイクが確認された場合にのみ制限を適用してください。そして、常にスロットリングを監視してください(container_cpu_cfs_throttled_seconds_total)。
HPA(Horizontal Pod Autoscaler)は、CPUのリクエストの割合に基づいてスケーリングを行います。リクエストが低すぎると、90%の使用率でも、余分に1つのポッドしかスピンアップしない場合があります。
落とし穴: リクエストが設定されていない場合、HPAは何もしません(「未定義の使用率」)。 ヒント: HPAは常に適切なリクエストと組み合わせて使いましょう。例えば、サービスが約50mでアイドル状態にあり、ピークが500mの場合、リクエストを200mに設定し、ターゲットCPU利用率を60%に設定します。


apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: web-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-service
minReplicas: 3
maxReplicas: 12
metrics:
- type: ContainerResource
containerResource:
name: cpu
container: app # per-container metrics (K8s ≥1.30)
target:
type: Utilization
averageUtilization: 60
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # wait 5 min before down‑scaling
policies:
- type: Percent
value: 20
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60 # wait 1 min before up‑scaling
policies:
- type: Pods
value: 2
periodSeconds: 60
- type: Percent
value: 50
periodSeconds: 60
selectPolicy: MaxapiVersion: v1
kind: LimitRange
metadata:
name: default-limits
namespace: team-apps
spec:
limits:
- type: Container
default:
cpu: "400m"
memory: "512Mi"
defaultRequest:
cpu: "100m"
memory: "128Mi"
min:
cpu: "50m"
memory: "64Mi"
max:
cpu: "2000m"
memory: "2Gi"リソース設定とHPAの動作を負荷の下で検証するために、次のアプローチを検討してください:
重要なのは、徐々に負荷をかけるテストと突然の負荷変化をテストし、設定がさまざまなトラフィックパターンに適切に反応するか確認することです。
あるフィンテック顧客は、各Podで30秒間400%のCPUスパイクが発生し、その後60%に落ち着くデータ取り込みジョブを実行していました。リクエストを100m、リミットを200m、HPAターゲットを75%に設定していましたが、ポッドは初期化時に繰り返し再起動し、HPAは作動しませんでした。
Aokumoのアプローチ:
結果: 再起動ゼロ、負荷下で3→12ポッドへのスムーズなオートスケーリング、無駄なCPU使用を20%削減
2025年には、すべてのリソース設定に一律の設定は通用しません。実際のワークロードパターンに基づいてリクエスト、リミット、HPAルールを設定することで、スロットリングを回避し、ノイジー・ネイバーを抑え、真のオートスケーリングを実現できます。
次のステップ:
1ワークロードを72時間プロファイルする
実践的な支援が必要ですか?AokumoのKubernetesの専門家による無料リソース監査をスケジュールし、クラスターを自己調整型パワーハウスに変えましょう。スロットリングの問題を特定し、コストを最適化し、ワークロードに最適なスケーリング戦略を実装するお手伝いをいたします。