AI Agents
Kubernetes × AI:推論からインテリジェンスへ、スケールするAI基盤の進化
かつてはコンテナオーケストレーターだったKubernetesが、AIワークロードのためのユニバーサルプラットフォームへと進化した軌跡。
Younes Hairej11 min read
かつてはコンテナオーケストレーターだったKubernetesが、AIワークロードのためのユニバーサルプラットフォームへと進化した軌跡。
KubeCon Japan 2025 は明らかな新しい現実を示しました。AIワークロードは現代のインフラの中心となり、Kubernetesはそのユニバーサルコントロールプレーンとして存在感を増しています。Bloomberg による本番環境での AI ゲートウェイの導入から、DaoCloud による6510億パラメータのモデルをマルチホストで推論実行する仕組みまで、この融合はインフラスタック全体を再構築しつつあります。
たとえば DeepSeek-R1 のようなモデルは、FP16では1.3TB、FP8でも651GBものVRAMを必要とするため、最適化以前の段階から複数ノード構成が前提となります。これは単に「大きなマシンが必要」という話ではなく、まったく新しいインフラカテゴリが誕生していることを意味します。東京で行われたセッションでは、AIアーキテクチャにおける本質的な変化が浮き彫りになりました。Bloomberg の Alexa Griffith 氏は、AIプラットフォームの進化を「3つの時代」に分けて紹介し、その変遷を示しました。
時代 | ワークロード規模 | 入出力 | データ構造 |
|---|---|---|---|
従来型 | 軽量 | JSON(矩形形式) | トランザクショナルDB |
予測型ML | MB~GB | テンソル | フィーチャーストア |
生成型AI | GB~TB | 流れるデータ | ベクトルDB |
生成AI時代には、従来とは根本的に異なるインフラが求められます。
これまでのアプリケーションではCPUの性能やリクエスト処理数が指標でしたが、AIワークロードではGPUのオーケストレーション、トークン単位でのレート制御、そして分離型のサービングアーキテクチャが必要になります。
ここで本領を発揮するのが Kubernetes です。
単なるコンテナオーケストレーターにとどまらず、AIプラットフォームを構築するための土台としての役割が際立ってきています。
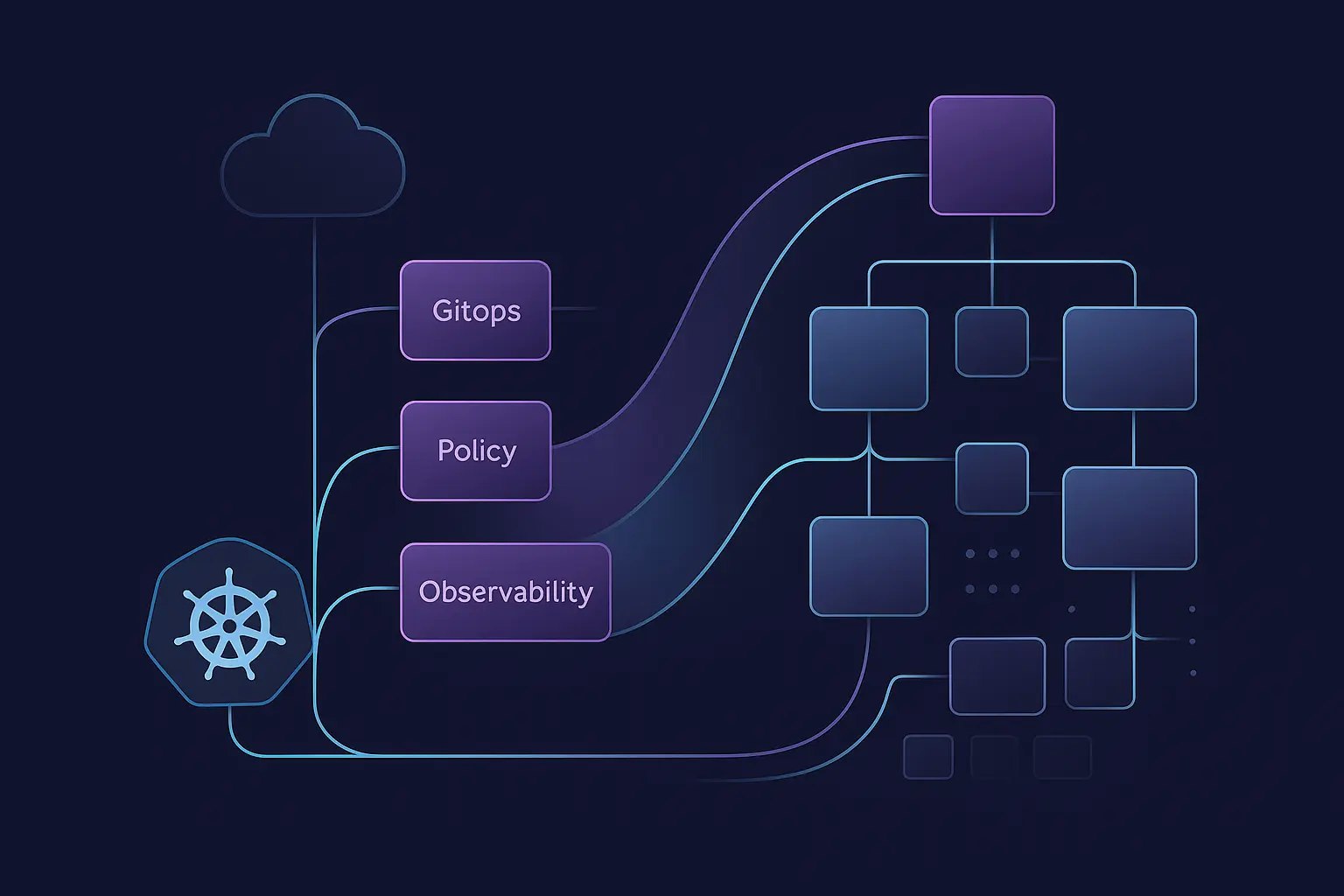
Aokumoでは、この融合を次の3つの視点で捉えています:
「Kubernetes上のAI」「Kubernetesの下にあるAI」「Kubernetesの中にあるAI」
この考え方は、インテリジェントでスケーラブルなインフラをスタック全体にわたって構築する、私たちのアプローチを表しています。
AIワークロードは、特殊な要求を持つコンテナです。规模なオブザービリティ、CI/CD、セキュリティ等はそのまま適用されます。
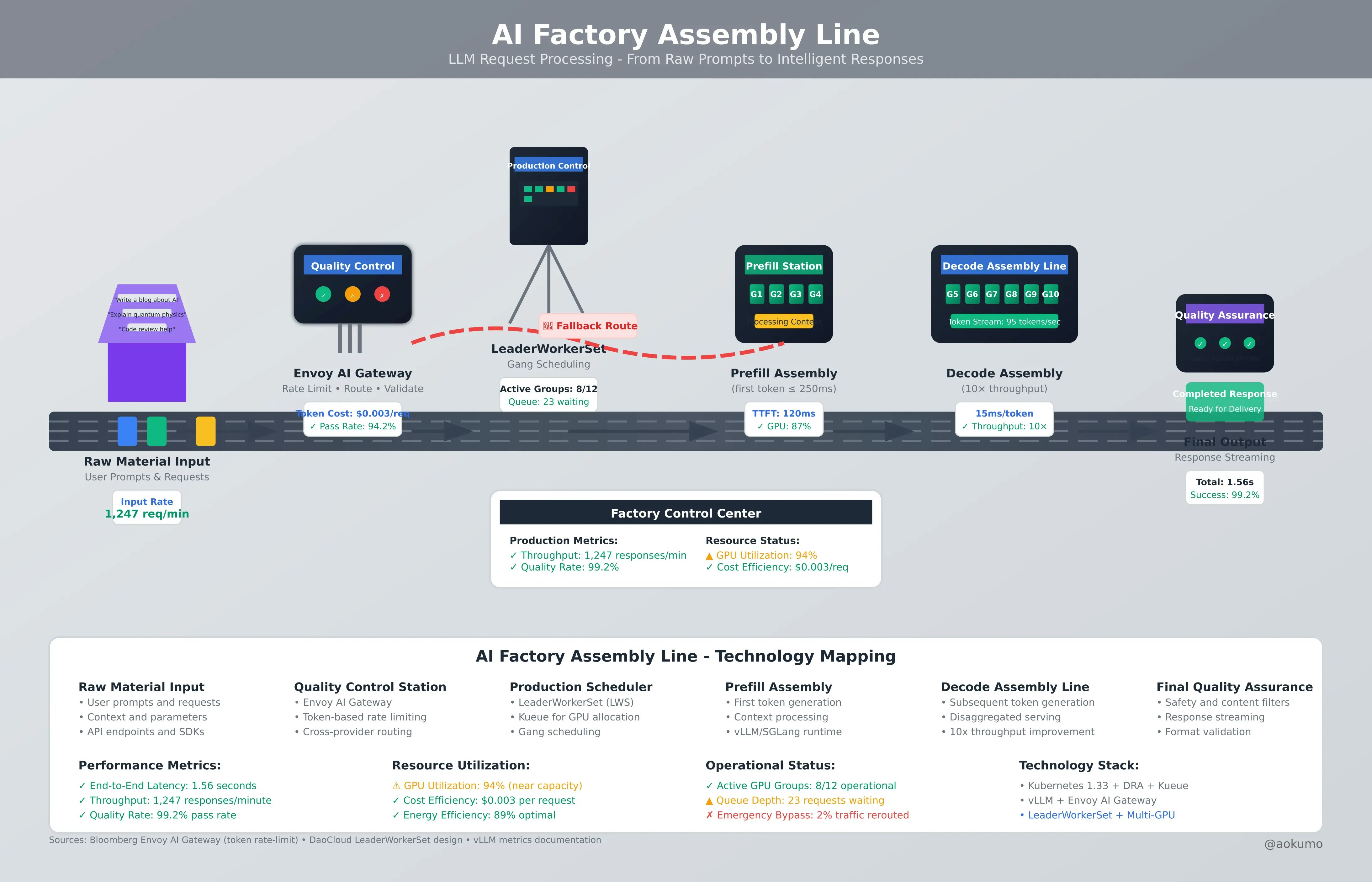
Bloombergは Envoy AI Gateway を用いて、LLMトラフィックを管理:
重要な洞察:
「生成AIシステムの可用性を確保するには、レジリエンス(復元力)が不可欠だ。クロスリージョンやクロスモデルのプロバイダー間での“優先度ベースのフォールバック”が鍵になる。」
— Dan Sun(Bloomberg)
つまり、障害や遅延が発生してもサービスを継続できるように、優先順位に基づいて他のリージョンやモデルへ自動的に切り替える設計が、生成AI時代の信頼性を支えるということです。
従来のCPU/メモリベースのスケジューリングは、複数ノードにまたがるGPUの分離型サービングや、複雑なトポロジー要件に対応しようとすると、機能しなくなります。
この課題に対し、DaoCloudの「LeaderWorkerSet(LWS)」が次のような仕組みで対応しています:
マルチホストにおける分散推論のパターン:
このように、Kubernetesの下層でGPUリソースを効率かつ安全に扱うための高度な仕組みが求められています。
分離型サービングアーキテクチャにより、スループットが10倍向上(DaoCloud ベンチマーク、2025年6月)
これは、"prefillフェーズ"(プロンプト処理)と "decodeフェーズ"(トークン生成)を異なるGPUプールに分けて処理することで実現されました。各フェーズの特性に最適化されたリソース配置により、大幅な性能向上が得られています。
AIに特化した指標によるオートスケーリング
従来の「GPU使用率」では不十分なため、以下の LLM向けメトリクス を使ったスケーリングが推奨されています:
AIプラットフォーム全体をKubernetesに組み込む:
完全な機械学習ライフサイクルには「推論」だけでは不十分
Kubeflow エコシステムの進化は、Kubernetes がエンドツーエンドのAIプラットフォームの基盤となることを示しています。
Training Operator 2.0(DeepSpeedをネイティブサポート)
KServe(本番環境での推論サービング)
Ray Data(データストリーミング課題の解決)
パターン:複数クラスタにAIワークロードを分散させ、レジリエンス向上、コスト最適化、地理的分散を実現。
実装例:
課題:GPUリソースは高価かつ限られているため、CPU指標に基づく従来のオートスケーリングは失敗しやすい。
解決策:
推論だけでなく、実運用AIプラットフォームに必要な要素:
AI特有の重要なメトリクス:
(KubeCon Japan 2025で示されたパターンをもとに)
この変革が重要なのは、単なる技術的な進歩だけでなく、経済的・運用的な優位性をもたらす点にあります。
AIとKubernetesの融合は、単なる技術の進化ではなく、今後10年のコンピューティングを形作るAIネイティブプラットフォームの基盤です。
KubeCon Japan 2025での主要な兆候
プラットフォームチームにとっての大きなチャンス
今、AI対応のKubernetesプラットフォームを構築する組織は、AIワークロードがインフラ需要の主役になる未来において、大きなアドバンテージを手にします。
もはや「AIワークロードをサポートするかどうか」ではなく、「それに備えられているかどうか」が問われる時代です。
あなたの組織ではどのようなAIワークロードパターンが見られますか?
AIネイティブな未来に向けて、どのようにプラットフォームを準備していますか?