DevOps
Fleet-Ready by Design: Evolving the Kubernetes Platform Stack
From single-cluster operations to multi-cluster fleet management: A pragmatic guide to evolving your platform stack.
Younes Hairej3 min read
From single-cluster operations to multi-cluster fleet management: A pragmatic guide to evolving your platform stack.
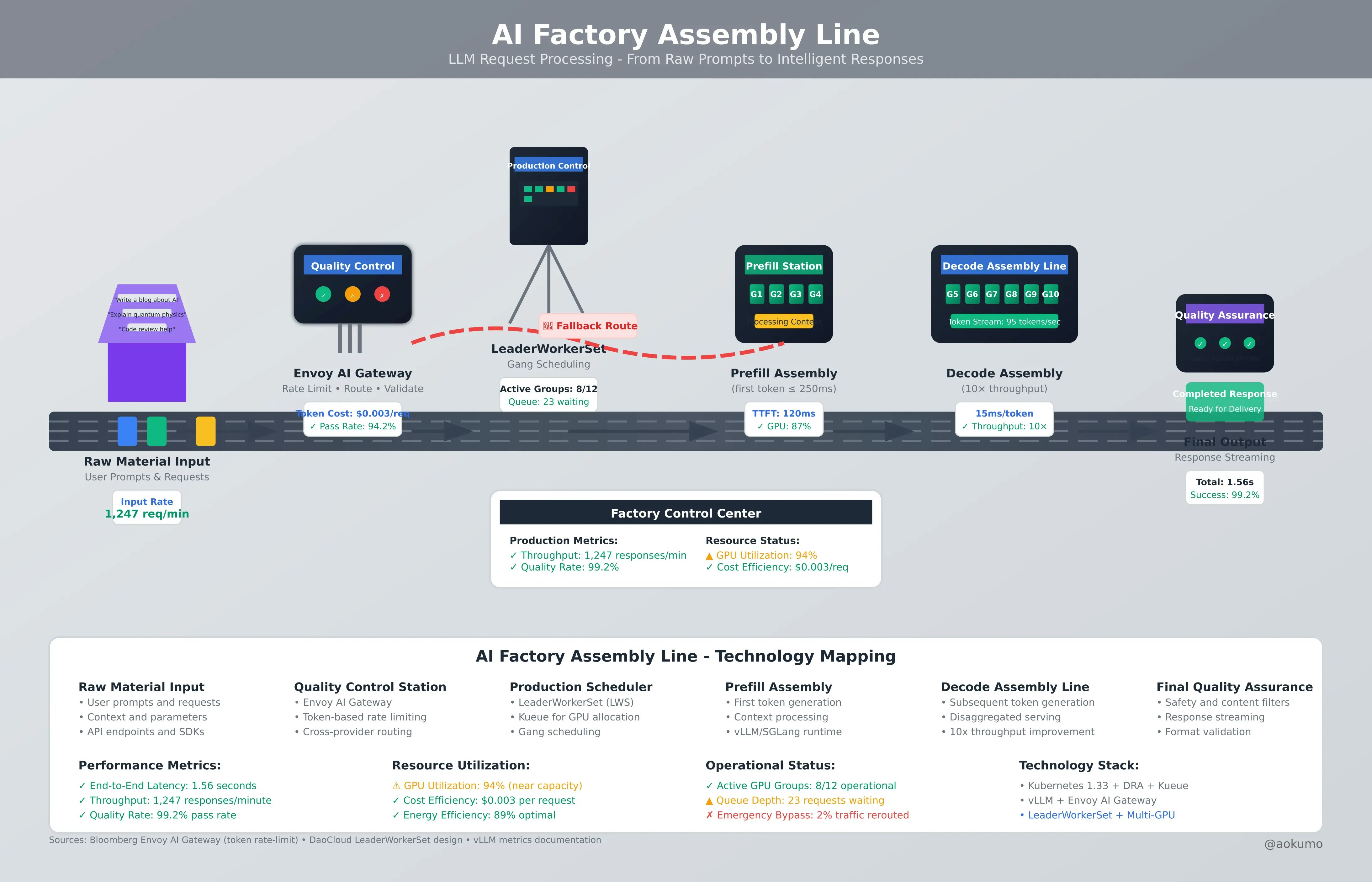
The conversations at KubeCon Japan 2025 made one thing clear: platform teams are moving beyond single-cluster thinking. But how do you build a fleet-ready platform? After an extensive analysis of current tooling and emerging patterns, here is our practical roadmap for extending a solid baseline stack into a comprehensive, multi-cluster platform.
Before adding complexity, let's acknowledge what already works well. Our current stack at Aokumo represents industry best practices that have proven themselves at scale:
Layer | Tool | Why It Works |
|---|---|---|
Cloud Resources | Declarative, multi-cloud IaC; Compositions ship full "platform slices" in one CRD | |
Node Provisioning | Fast, right-sized nodes; NodePools give fleet-wide constraints and consolidation | |
GitOps | Mature multi-cluster patterns (ApplicationSets) with strong RBAC | |
Policy | Kubernetes-native, label-driven; v1.12 brought large-fleet performance gains |
Keep these. They're battle-tested, map cleanly to the "Kubernetes-for-Kubernetes" vision, and integrate well with emerging multi-cluster standards.
Moving to fleet-scale operations reveals specific gaps that need addressing:
Cluster Lifecycle → Add Cluster API + ClusterClass; declarative create/upgrade; integrates with Crossplane.
New Cluster Bootstrap → Add CAPI Fleet addon; auto-registers clusters so applications land immediately.
Cost Visibility → Add OpenCost v1.0+; unified multi-cluster spend reporting and chargeback.
Cross-Cluster Networking → Add Cilium ClusterMesh; eBPF-powered pod-to-pod connectivity with identity policies.
Most enhancements can be added incrementally without disrupting existing workloads:
Add | Benefit | Integrates With |
|---|---|---|
Backstage Kubernetes plugins | One portal for environment requests, logs, workflows | Triggers Crossplane via GitOps PRs |
Global query with long-term retention across clusters | OpenTelemetry collectors per cluster | |
Gateway API v1.3 controllers | Standardized L4-L7 routing with same YAML everywhere | Works with Cilium ClusterMesh traffic |
Fair-share GPU scheduling with fine-grained control | Karpenter provisions GPU nodes on-demand |
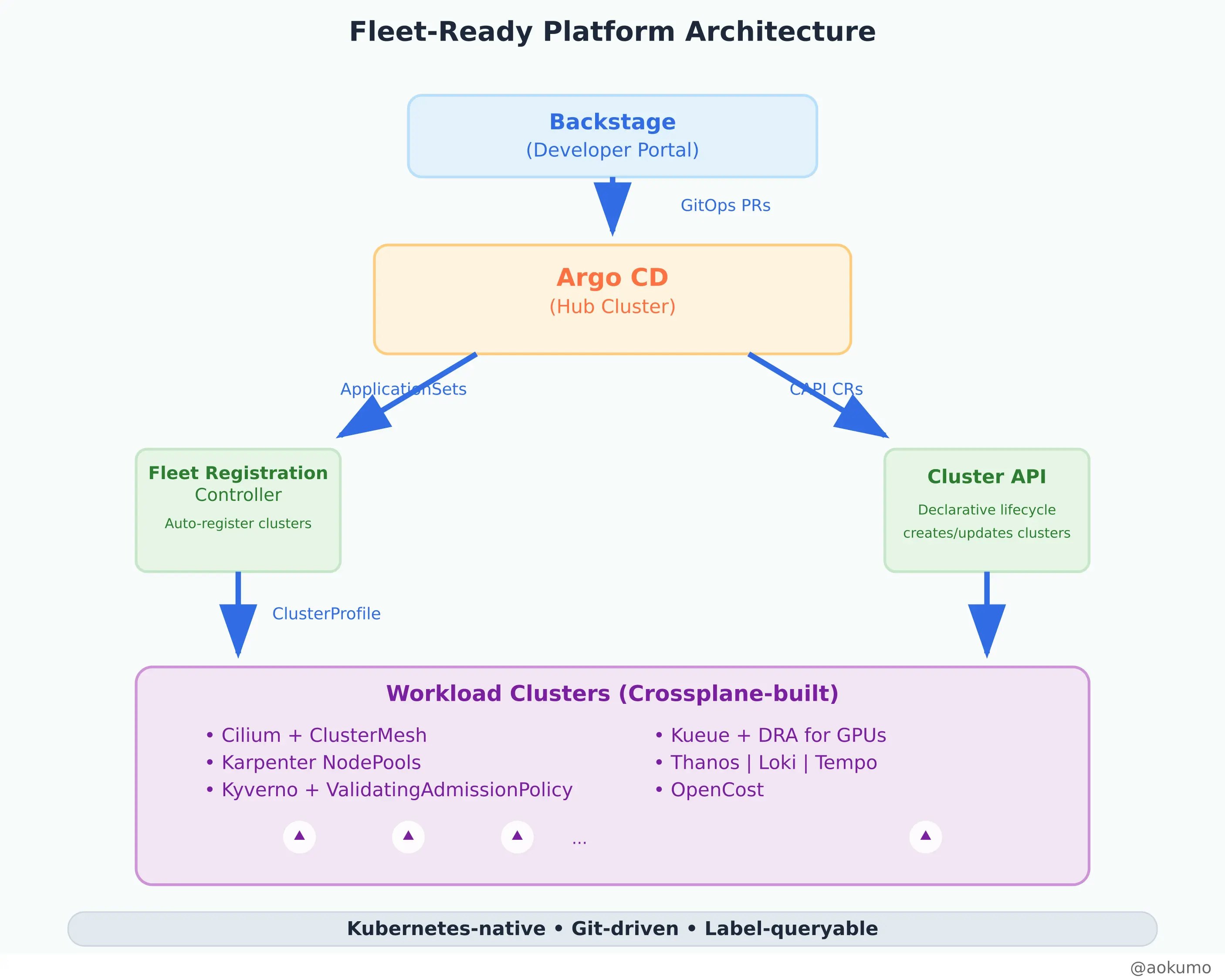
Here's how all these components work together in a fleet-ready platform:
Everything remains Kubernetes-native, Git-driven, and label-queryable, maintaining the core principles while scaling to fleet operations.
Composite Clusters: Use Crossplane Compositions to wrap CAPI Clusters with infrastructure (VPC, EKS, IAM). One claim creates a fully bootstrapped cluster.
Fleet-Aware Resources: Annotate Crossplane XRs with cluster-profile labels to sync with SIG-Multicluster's ClusterProfile CRD.
Dual Engines: Pair Kyverno with ValidatingAdmissionPolicy (beta in v1.33) for latency-free validation.
External Storage: Use Kyverno 1.12 reports-server to avoid etcd bloat on large fleets.
Control Loop Coordination: Run VPA → HPA → Karpenter in sequence rather than parallel:
Event-Driven Scaling: Add KEDA as an HPA source—Karpenter only provisions nodes when KEDA determines replicas are required.
Runtime Security: Cilium Tetragon provides eBPF-based runtime security and tracing.
Simplified Service Mesh: Envoy Gateway consumes Gateway API resources directly—simpler than full Istio for L7 routing needs.
Operational Efficiency:
Developer Productivity:
Platform Reliability:
The transition from single-cluster to fleet-ready platforms isn't about replacing what works—it's about extending proven foundations with complementary capabilities. By building on Crossplane, Karpenter, ArgoCD, and Kyverno, we can add multi-cluster lifecycle management, cross-cluster networking, and unified observability without disrupting existing workloads.
The key insight from KubeCon Japan 2025 was that standardization enables scale. The ClusterProfiles API, Multi-Cluster Services, and Gateway API aren't just technical specifications—they're the foundation for the next generation of platform engineering.
What's your experience with multi-cluster platform challenges? Are you seeing similar patterns in your organization?
Request a Demo to see how we can help you with your multi-cluster Kubernetes needs