AI Agents
AI on Kubernetes: From Inference to Intelligence at Scale
How Kubernetes evolved from a container orchestrator to a universal platform for AI workloads.
Younes Hairej6 min read
How Kubernetes evolved from a container orchestrator to a universal platform for AI workloads.
KubeCon Japan 2025 confirmed a new reality: AI workloads define modern infrastructure, and Kubernetes has become their universal control plane. From Bloomberg's production AI gateway to DaoCloud's multi-host inference serving 651-billion parameter models, the convergence is reshaping the entire stack.
Models like DeepSeek-R1 require 1.3TB of VRAM in FP16 or 651GB in FP8 just to run—necessitating multiple nodes before performance optimization. This isn't bigger hardware—it's an entirely new infra category.
Tokyo sessions exposed a fundamental shift in AI architecture. Bloomberg's Alexa Griffith demonstrated platform evolution through three distinct eras:
Era | Workload Scale | Input/Output | Data Architecture |
|---|---|---|---|
Traditional | Lightweight | Short, defined JSON | Transactional databases |
Predictive ML | MB-GB | Tensor | Feature stores |
Generative AI | GB-TB | Variable, streamed | Vector databases |
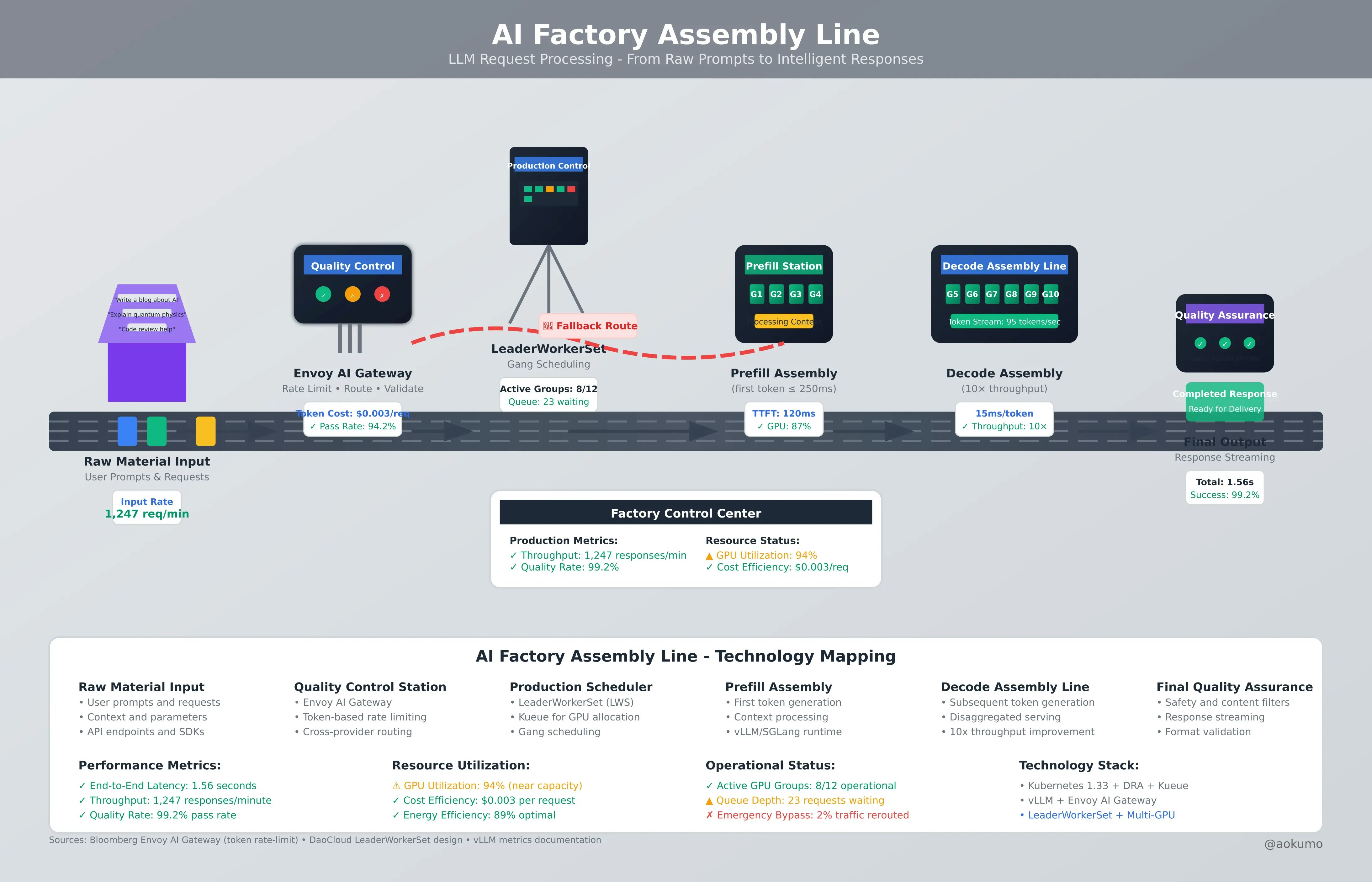
The GenAI era demands fundamentally different infrastructure. Where traditional apps measured CPU capacity and request throughput, AI workloads require GPU orchestration, token-based rate limiting, and disaggregated serving architectures.
This is where Kubernetes' true power emerges—not just as a container orchestrator, but as the platform for building AI platforms.
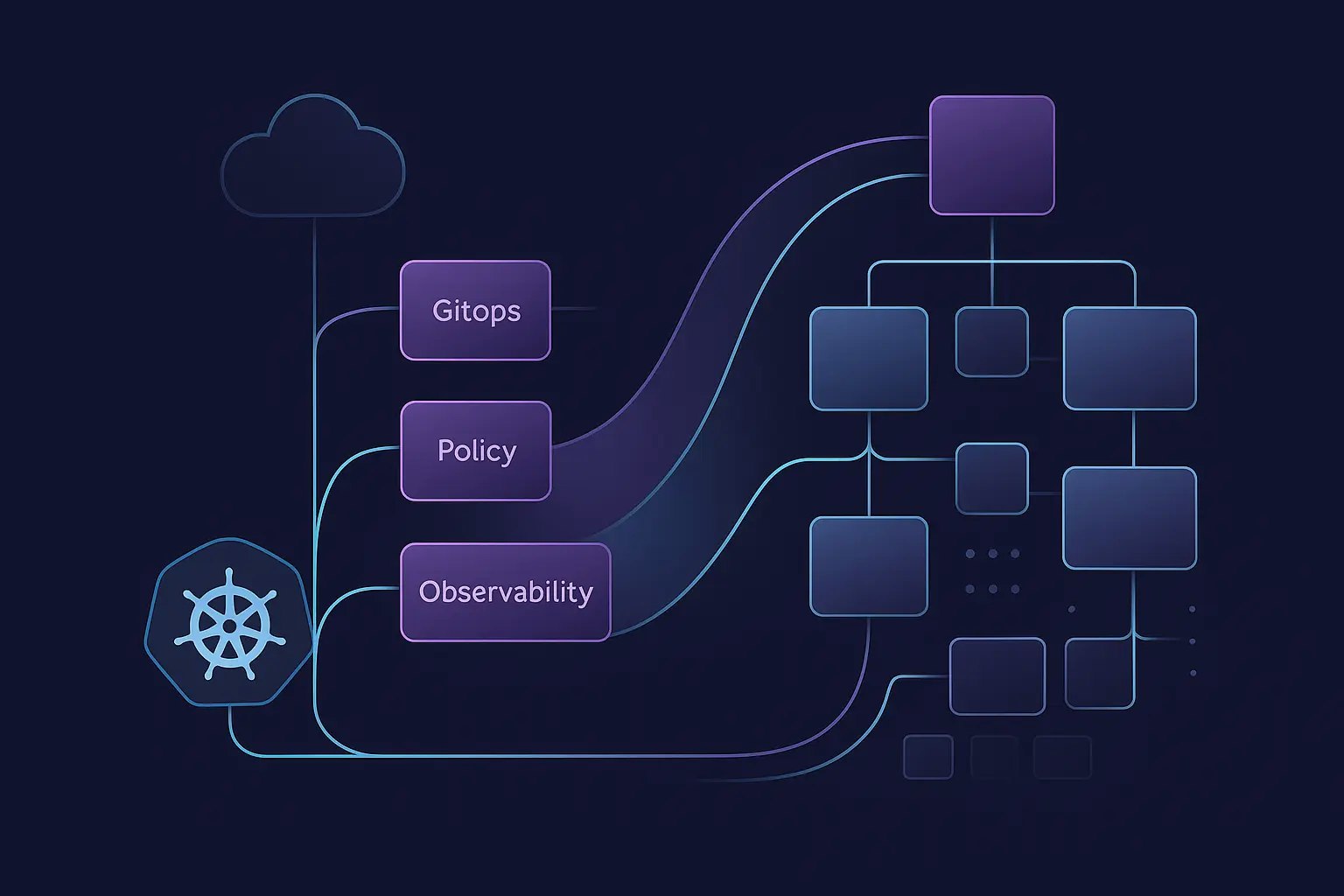
At Aokumo, we see this convergence through three lenses: AI on Kubernetes, AI below Kubernetes, and AI in Kubernetes.
This framing captures how we approach building intelligent, scalable infrastructure across the stack.
AI workloads are ultimately containers with special requirements. All production-grade practices—observability, CI/CD, security—apply directly to inference services and training jobs.
Bloomberg's Envoy AI Gateway handles enterprise LLM traffic with:
apiVersion: aigateway.envoyproxy.io/v1alpha1
kind: AIGatewayRoute
spec:
llmRequestCosts:
- cel: input_tokens / uint(3) + output_tokens
metadataKey: tokenCost
rules:
- backendRefs:
- name: azure-backend
priority: 0
weight: 2
- name: openai-backend
priority: 1 # FallbackKey insight: "Resilience is critical for GenAI system availability. Priority-based fallback for cross-region or cross-model providers." - Dan Sun, Bloomberg
Traditional CPU/memory scheduling breaks down when you need disaggregated GPU serving across multiple nodes with complex topology requirements.
DaoCloud's LeaderWorkerSet (LWS) addresses this with:
Multi-host distributed inference patterns:
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: deepseek-r1-inference
spec:
replicas: 2 # Number of model instances
leaderWorkerTemplate:
size: 8 # 1 leader + 7 workers per instance
restartPolicy: RecreateGroupOnPodRestartDisaggregated serving architecture delivers 10x throughput improvement (DaoCloud benchmarks, Jun 2025) by separating prefill and decode phases across different GPU pools.
Auto-scaling with AI-specific metrics:
Check out the vllm documations for details.
The complete ML lifecycle requires more than inference. Kubeflow's ecosystem evolution demonstrates how Kubernetes becomes the foundation for end-to-end AI platforms:
Training Operator 2.0 with native DeepSpeed support:
KServe for production inference:
Ray Data solves the data streaming challenge:
Common Gotchas
The pattern: Run AI workloads across multiple clusters for resilience, cost optimization, and geographic distribution.
Implementation:
The challenge: GPU resources are expensive and scarce. Traditional autoscaling based on CPU metrics fails catastrophically.
The solution:
Beyond just inference: Production AI platforms need:
AI-specific metrics that matter:
Based on the patterns emerging from KubeCon Japan 2025, here's a practical roadmap:
Establish GPU-aware scheduling:
Add AI-specific networking:
Scale to production workloads:
Build developer experience:
What makes this transformation significant isn't just the technical capabilities—it's the economic and operational advantages.
The convergence of AI and Kubernetes represents more than technological evolution—it's the foundation for AI-native platforms that will define the next decade of computing.
Key indicators from KubeCon Japan 2025:
The opportunity for platform teams is enormous. Organizations that build AI-ready Kubernetes platforms now will have significant advantages as AI workloads become the primary driver of infrastructure demand.
The question isn't whether your platform will need to support AI workloads—it's whether you'll be ready when they arrive.
What AI workload patterns are you seeing in your organization? How are you preparing your platform for the AI-native future?
Next in our KubeCon Japan 2025 series: "Edge Computing Revolution: Kubernetes Everywhere" - exploring how cloud-native infrastructure is reaching into factories, vehicles, and IoT devices worldwide.
Let’s explore how we can scale your AI workloads securely and cost‑effectively. Contact us now!