Platform Engineering
Platform Engineering 2025: Beyond GitOps Into Intelligence
How platform teams are evolving from reactive operations to AI-assisted infrastructure management.
Younes Hairej5 min read
How platform teams are evolving from reactive operations to AI-assisted infrastructure management.

Platform engineering has reached an inflection point. While the industry spent the last five years perfecting GitOps workflows and Infrastructure as Code, KubeCon Japan 2025 revealed the next evolutionary leap: intelligent platforms that predict, adapt, and optimize themselves.
This isn't about replacing human expertise—it's about augmenting platform teams with AI-powered insights that transform reactive operations into proactive orchestration.
Generation | Focus | Tools | Mindset | Limitations |
|---|---|---|---|---|
First (2015-2020) | Automate manual processes | Ansible, Terraform, Jenkins | "Infrastructure as Code" | Reactive problem-solving |
Second (2020-2024) | Declarative infrastructure and self-service | ArgoCD, Flux, Backstage, Crossplane | "Platform as Product" | Static policies, manual optimization |
Third (2024+) | AI-assisted operations and autonomous optimization | K8s GPT, ForecastAI Sched., OpenCost AI | "Platform as Intelligence" | Early-stage tooling, skills gap |
Traditional Approach:
Incident occurs → Alert fires → Human investigates → Manual fix → Post-mortemIntelligent Approach:
Pattern detected → Prediction generated → Automated prevention → Continuous learningTeams implementing predictive operations report a 60% drop in pager noise and mean time to resolution dropping from hours to minutes.
Traditional Platform Engineering:
Intelligent Platform Engineering:
Organizations implementing intelligent optimization report a reduction of up to 40% in infrastructure costs while improving application performance (KubeCon '25 survey, n = 27 organizations).
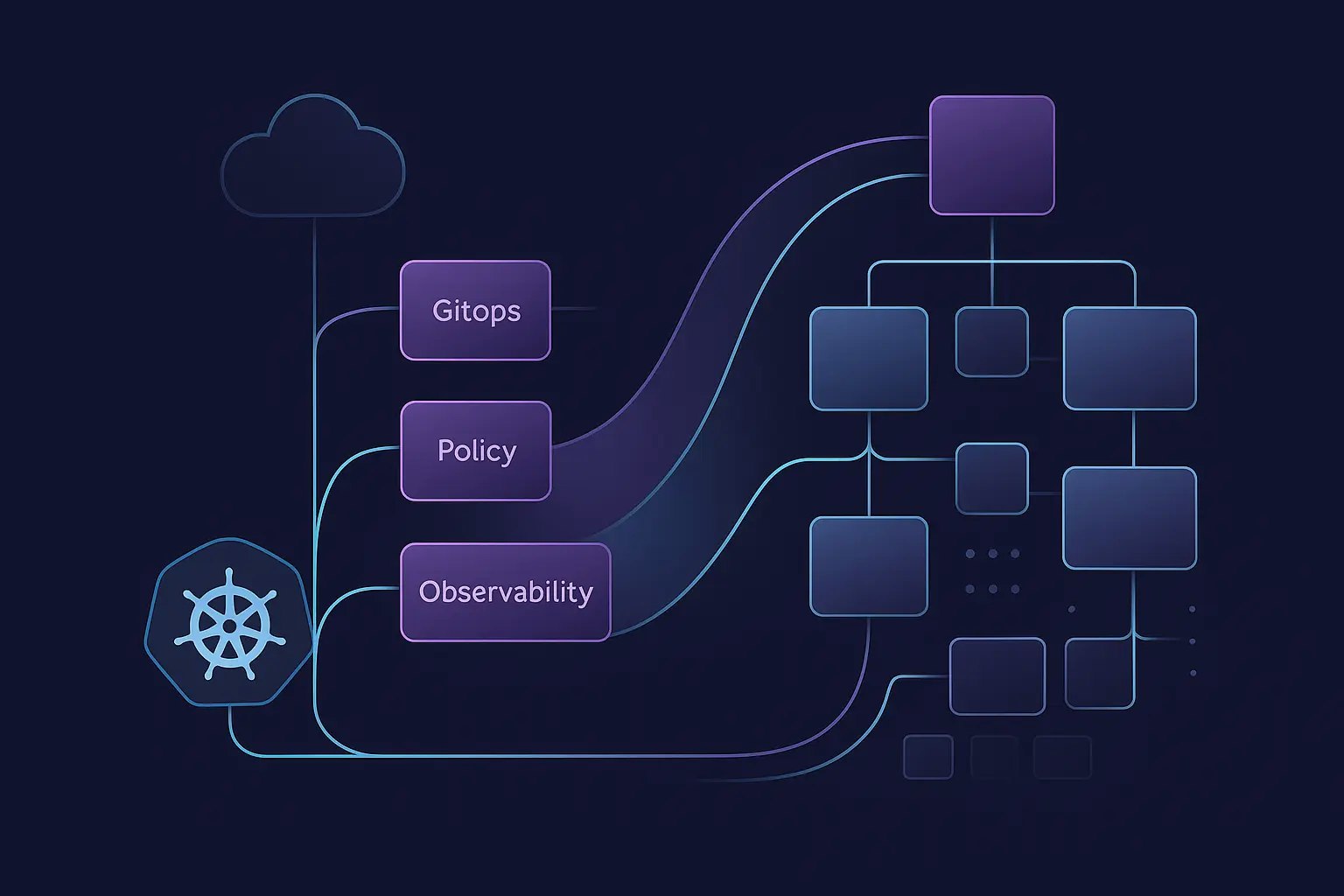
The emergence of tools like K8s GPT and Aokumo AI represents a fundamental shift in how platform teams interact with infrastructure, moving from YAML configuration to natural language conversations.
Example Interaction:
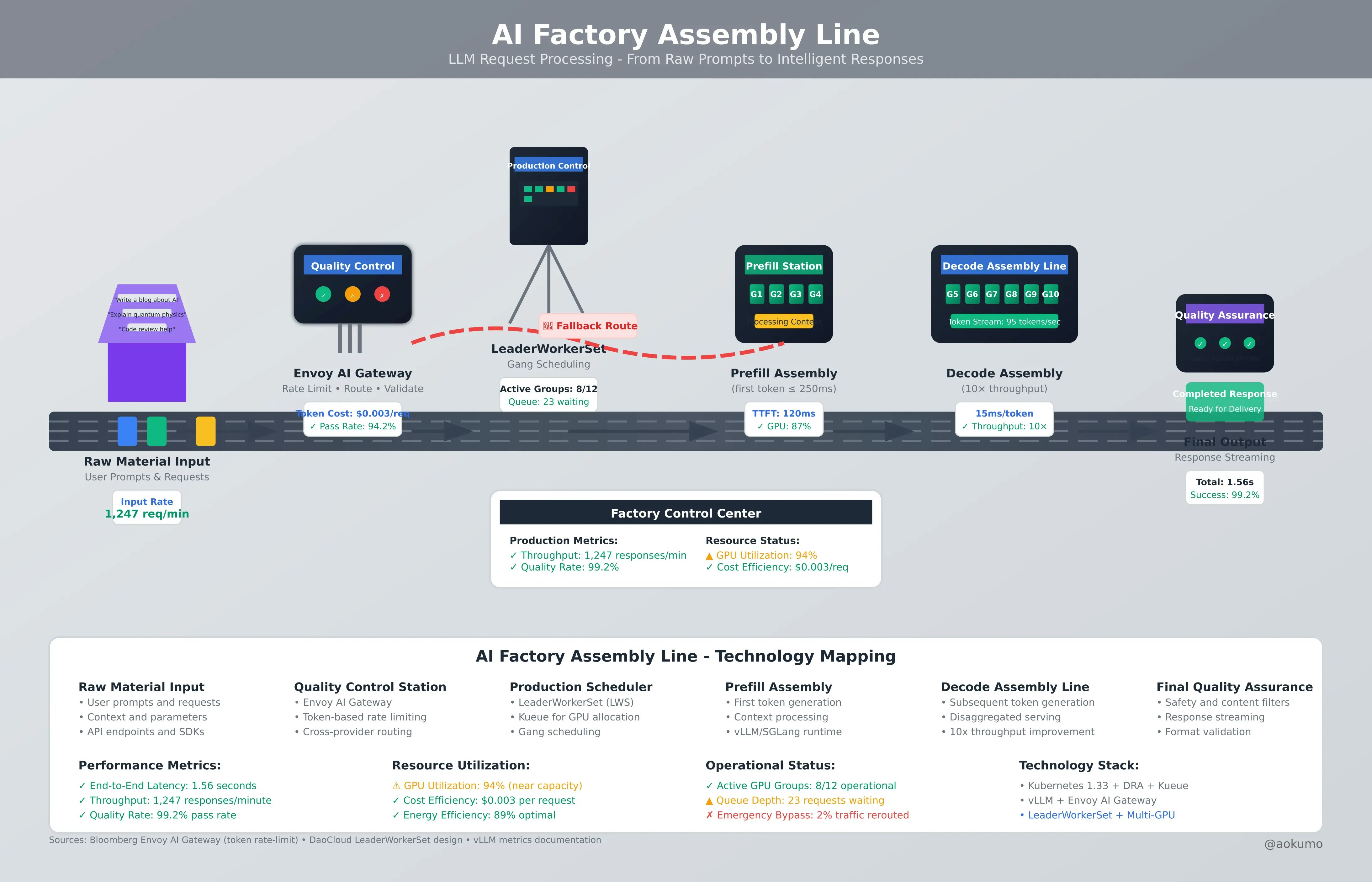
Platform Engineer: "Our GPU utilization is low but costs are high"
AI Assistant: "Analysis shows 60% of GPU time is idle during prefill phases.
Implementing disaggregated serving would increase utilization to 94%
and reduce costs by $12k/month. Shall I generate the LeaderWorkerSet configuration?"Platforms like Aokumo are already enabling this conversational infrastructure management, allowing teams to express intent in natural language and receive optimized Kubernetes configurations automatically.
Why it matters: platform teams stop gatekeeping YAML and start shipping business outcomes.
Developers express business requirements, and intelligent platforms translate them into optimal technical implementations.
Example Intent:
apiVersion: platform.aokumo.io/v1
kind: ApplicationIntent
metadata:
name: customer-api
spec:
requirements:
availability: "99.9%"
latency: "p99 < 100ms"
cost: "minimize"
compliance: "SOC2"
workload:
type: "stateless-api"
traffic: "global"AI-Generated Implementation:
Platform teams at KubeCon Japan 2025 demonstrated clusters that continuously adjust resource allocation based on workload patterns.
Key Capabilities:
A global consumer technology company presented their evolution toward tenant-centric multi-cluster management powered by intelligent automation.
Key Result: Their platform learns from tenant behavior patterns to optimize placement, predict capacity needs, and prevent issues before they impact users.
Central Intelligence Hub
├── Pattern Recognition Engine
├── Policy Optimization
└── Global Resource Coordination
Distributed Execution Clusters
├── Local Resource Management
├── Workload-Specific Optimization
└── Feedback Loop to HubThis enables global optimization while maintaining local responsiveness.
Traditional: Quarterly reviews, over-provisioning, manual projections
Intelligent:
A large financial data provider's Envoy AI Gateway implementation revealed patterns invisible to traditional monitoring:
Next-generation security integrates directly into platform operations:
Monitoring (Prometheus, Grafana)
GitOps (ArgoCD, Flux)
IaC (Terraform, Crossplane)
Orchestration (Kubernetes)
Infrastructure (Cloud, On-Prem)
Intelligence Layer
• Predictive Analytics • Pattern Recognition • Optimization Engines
Enhanced Monitoring
• Behavioral Analysis • Intent Correlation
Intelligent GitOps
• AI-Generated Configs • Predictive Deployments
Adaptive IaC
• Dynamic Resource Allocation • Cost-Aware Provisioning
Enhanced Orchestration
• Intelligent Scheduling • Workload Optimization
Infrastructure (Cloud, Edge, On-Prem)Organizations implementing intelligent platforms report:
Technical Challenges | Organizational Challenges |
|---|---|
Data Quality: AI systems require high-quality, consistent telemetry | Skills Evolution: Platform teams need AI/ML literacy |
Model Training: Requires sufficient historical data | Change Management: Shifting from reactive to predictive mindsets |
Integration Complexity: Coordinating AI across diverse components | Trust Building: Confidence in AI-driven decisions |
Next 2-3 Years: AI assistants become standard platform tooling, predictive capabilities mature for common scenarios.
Next 5-10 Years: Self-optimizing infrastructure becomes the norm, platform engineers focus on business logic rather than operational tasks.
From: Infrastructure operators and configuration managers
To: Platform product managers and AI system architects
New Responsibilities:
Platform engineering is evolving from reactive operations to AI-powered intelligence. Organizations embracing this transformation deliver superior developer experiences while dramatically reducing operational overhead.
The competitive advantages:
The transformation requires:
Early adopters are already gaining competitive advantages through intelligent platform engineering. The question isn't whether to evolve—it's how quickly you can transform your platform operations for the AI-native future.
What intelligent capabilities is your platform team building? How are you preparing for the shift from reactive to predictive operations?